Multimodal AI
Multimodal AIは画像・テキスト・音声などの性質の異なる複数の情報を使うことで、画像認識・物体検出・音声認識などの精度を向上させます。

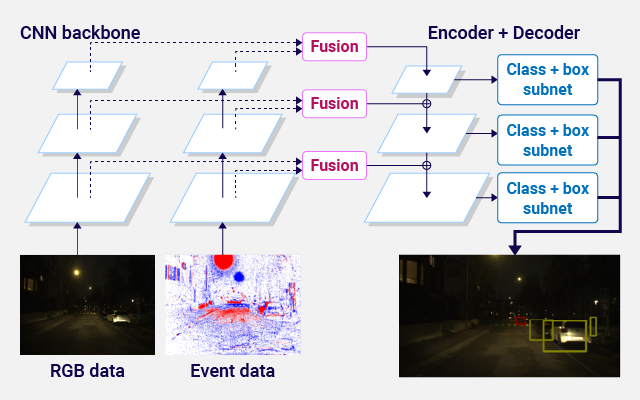
画像・テキスト・音声などの性質の異なる複数の情報を使って学習することで、画像認識・物体検出・音声認識などの精度を向上させます。フレームカメラから得たRGB画像を使って学習したモデルを用いると、夜の物体検出精度が低く留まります。RGB画像に加えて、ダイナミックレンジの高いイベントカメラから得たイベントデータを用いて学習することで、夜の物体検出精度を高めることができます。さらに、マルチモーダル情報の融合方法の工夫やモデルの重みの量子化により、エッジでのマルチモーダルAIを用いた物体検出を低電力・高精度に行うことができます。