Large language model
膨大な量のデータを使って学習されたLarge Language ModelのTransformerを基盤とする演算に適したComputation-in-Memoryアーキテクチャを開拓しています。

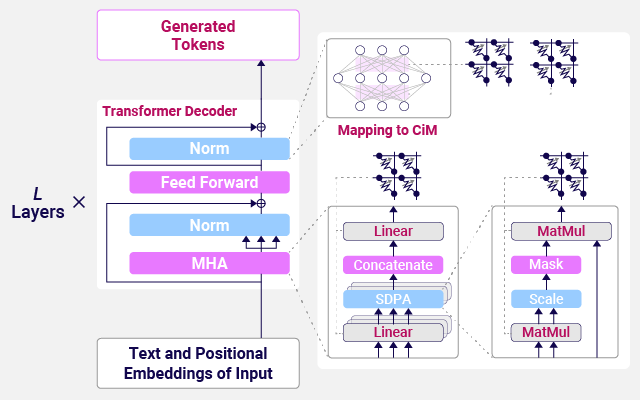
Transformerを基盤とするLarge Language Model (LLM)は膨大な量のデータを使って学習されたモデルで、特にSmall Language Model (SLM)はモデルパラメータ数が少ないためエッジデバイスへの実装が期待されます。Computation-in-Memory (CiM)を用いてTransformerの積和演算を行う場合、メモリの非理想性がLLMあるいはSLMの推論性能に影響を与えます。モデルサイズやメモリエラー耐性の観点から、CiMアーキテクチャの設計における重要な指針を提示し、今後の実用化に向けた基盤技術の確立を目指します。