Edge AI
Edge AI operates intelligent algorithm that senses and controls IoT (Internet of Things) devices such as autonomous driving cars, security cameras, drones and industrial robots.

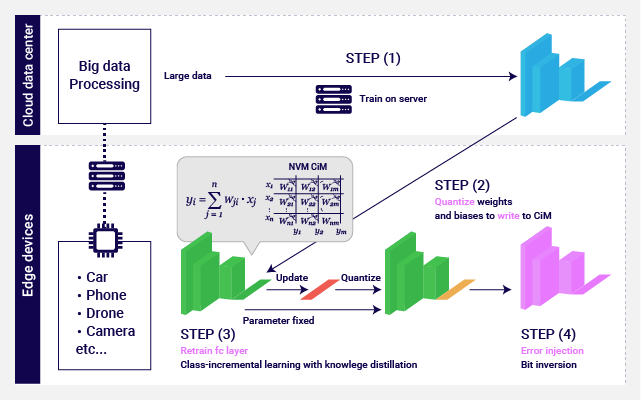
Edge devices need re-training of neural networks to adapt to changes in their usage and environment. Re-training using Computation in memory (CiM) does not require back-propagation because only the final layer of neural networks is re-trained. Thus, the number of rewrites to non-volatile memories in CiM reduces. Distillation of knowledge trained in the cloud data centers enables re-training of edge devices even when the edge devices do not have previously used training data.