Large language model
Computation-in-Memory architecture optimized for Transformer-based operations in Large Language Models trained on massive datasets is being developed.

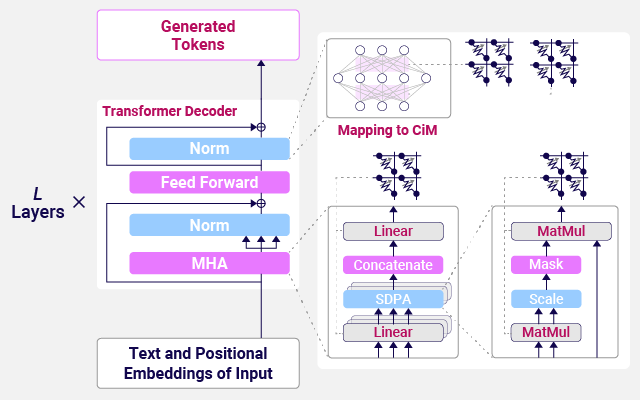
Transformer-based Large Language Model (LLM) is trained on massive datasets, while Small Language Model (SLM) with smaller parameter size is suitable for deployment on edge devices. When Computation-in-Memory (CiM) is used to perform the multiply-accumulate operations in Transformers, memory non-idealities can significantly impact the inference performance of both LLMs and SLMs. This research presents key design guidelines for CiM architectures, focusing on model size and robustness to memory errors, with the goal of contributing to the development of foundational technologies for future practical applications.