Multimodal AI
Multimodal AI improves accuracy of image recognition, object detection, and speech recognition by using multiple information of different character, such as images, text, and speech.

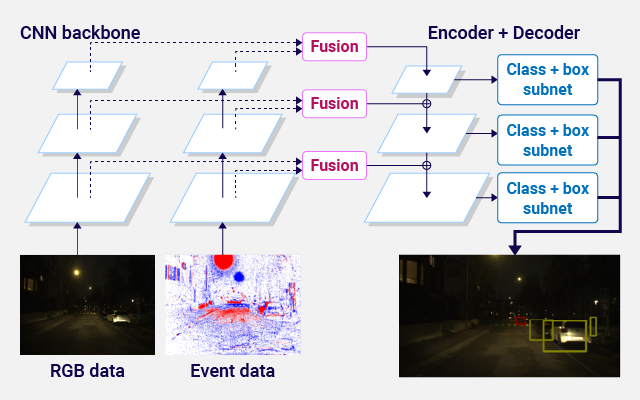
Multimodal AI improves the accuracy of image recognition, object detection, and speech recognition by training with multiple types of information, such as images, text, and speech. AI models trained with RGB images from frame cameras have low image recognition accuracy at night. In addition to RGB images, training with event data from high dynamic range event cameras improve object detection accuracy at night. In addition, object detection using multimodal AI at edges is achieved with low power and high accuracy by fusing multimodal information and quantizing weights of the model.